
 NoPe-NeRF: Optimising Neural Radiance Field with No Pose Prior
NoPe-NeRF: Optimising Neural Radiance Field with No Pose Prior
Abstract논문의 저자들은 카메라 포즈 정보 없이 NeRF를 통해 사진을 입체화하는 방법을 제안한다.1. Introduction(1) NeRF 학습의 전처리NeRF가 요구하는 전처리: COLMAP을 이용한 카메라 파라미터 추정COLMAP의 단점:처리 시간이 길다.미분 가능성(differentiability)이 없어 딥러닝과의 결합이 어렵다.(2) 카메라 포즈를 추정하는 기존의 연구연구된 모델: NeRFmm, BARF, SC-NeRF한계점: LLFF와 같은 forward-facing scene에서는 좋은 성능을 보였으나, 다이나믹한 카메라 이동에서 위치 추정 실패원인:이미지간의 상대적인 포즈를 고려하지 않고, 각 이미지마다 독립적으로 카메라 포즈를 추정함. SLAM과 Visual Odmetry는 이미지..
[4] NeRF Network¶1. Positional Encoding¶아래 코드는 NeRF 논문의 Positional Encoding 기법을 파이썬 클래스(Embedder)로 구현한 예시입니다.목표는 3차원 벡터(예: 위치 $\mathbf{p}$ 또는 방향 $\mathbf{d}$)에 대해, 다음과 같은 형태의 트리그 함수(사인/코사인) 묶음을 만들어 고차원 벡터로 확장하는 것입니다.$$\gamma(\mathbf{p})= \Bigl[\mathbf{p},\;\sin(2^0 \pi \mathbf{p}), \cos(2^0 \pi \mathbf{p}),\;\sin(2^1 \pi \mathbf{p}), \cos(2^1 \pi \mathbf{p}),\;\cdots,\;\sin(2^{L-1} \pi \mathbf{p..
[2] Calculating Rays¶1. 픽셀 좌표와 월드 좌표 대응하기¶NeRF는 장면의 픽셀에서 발사한 광선이 물체와 맞닿는 지점을 예측하여 렌더링을 진행합니다.이번 장에서는 카메라 매트릭스로부터 픽셀 좌표를 월드 좌표의 유일한 점으로 대응하고,이를 이용해 광선의 시작점과 방향을 계산하는 과정을 공부합니다.1) 픽셀 좌표 $(x,y,1)$ → 정규 좌표 $(u,v,1)$¶(a) 수식¶픽셀 좌표 $(x,y)$가 있을 때, 카메라 내부 행렬 $K$는 다음과 같은 형태를 가정합니다:$$K = \begin{bmatrix}f_x & 0 & c_x \\0 & f_y & c_y \\0 & 0 & 1\end{bmatrix}.$$그렇다면,$$\begin{bmatrix}x \\y \\1\end{bmat..
[1] 카메라 이론¶이번 장에서는 카메라를 월드의 원하는 지점으로 옮기는 행렬인 Cam to World Matrix(이하 c2w)에 대해 공부하겠습니다. 카메라가 어떤 특정 위치와 방향을 가질 때, 카메라 좌표계에서 본 3D 점을 세계 좌표계로 변환하려면 회전(Rotation) 과 평행이동(Translation) 을 적용해야 합니다.NeRF에서는 트레인 데이터에 없는 테스트용 카메라 위치를 계산하기 위해 render_poses 라는 변수를 만들고, 여기에 원하는 c2w를 저장합니다. 아래에서 c2w를 만드는데 필요한 요소를 살펴보겠습니다.1. 병진 행렬: trans_t(t)¶trans_t = lambda t : torch.Tensor([ [1,0,0,0], [0,1,0,0], [0,0,1..
 Addressing unfamiliar ship type recognition
Addressing unfamiliar ship type recognition
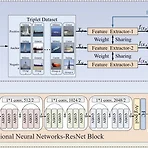
논문 제목: Addressing unfamiliar ship type recognition in real-scenario vessel monitoring: a multi-angle metric networks framework 감시 카메라로 밀입국한 중국 선박을 감지하는 인공지능 모델을 만들고 있는데, 전혀 다른 외형의 중국 어선을 few-shot learning으로 구별해낼 수 있을까 하여 해당 논문을 정리해본다. 제안된 방법론Triplet Generator각 클래스별로 분류된 선박을 Anchor, Positive, Negative의 세 이미지가 있는 묶음으로 재분할 한다. Anchor는 비교할 이미지, Positive에는 Anchor와 동일한 클래스의 이미지, Negative에는 Anchor와 다른..
개괄적인 개발 단계1. KoBERT-NER-mastergit: https://github.com/monologg/KoBERT-NER데이터셋: Naver NER 데이터셋 (tsv 파일, 비문으로 구성)코드 특성: 단순히 띄어쓰기 기준으로 문장 파싱목표:- 코드 분석- 법률 데이터를 tsv 파일로 전처리하여 해당 코드로 훈련 2. pytorch-bert-crf-nergit: https://github.com/eagle705/pytorch-bert-crf-ner데이터셋: 해양대학교 데이터셋 (txt 파일, 품사 정보 추가, 뉴스나 소설에서 발췌)코드 특성: 전용 토크나이저를 기반으로 문장 파싱목표:- 코드 분석- 모델 고도화 3. pytorch-ko-nergit: https://github.com/ai2-ne..