MAT: mat.py
코드를 읽기 전 사전 지식
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
DropPath: 이 함수는 네트워크의 학습 과정에서 일부 경로를 무작위로 "드롭"하는 기능을 수행합니다. 이는 네트워크의 일반화 능력을 향상시키기 위해 사용됩니다. DropPath는 Stochastic Depth 기법의 일부로 사용되며, 이는 특히 깊은 네트워크에서 과적합을 방지하고 학습 속도를 향상시키는 데 도움이 됩니다.
to_2tuple: 이 함수는 주어진 입력을 길이가 2인 튜플로 변환합니다. 예를 들어, 하나의 숫자가 주어지면, 이 함수는 이 숫자를 두 번 포함하는 튜플을 생성합니다. 이는 주로 이미지 처리나 신경망에서 입력 차원을 조정할 때 사용됩니다. 예를 들어, 하나의 크기 값을 받아서 커널 크기나 스트라이드 등을 2차원 형태로 변환하는 데 사용됩니다.
trunc_normal_: 이 함수는 절단 정규 분포(truncated normal distribution)를 사용하여 텐서를 초기화합니다. 절단 정규 분포는 정규 분포의 꼬리 부분을 잘라낸 형태로, 네트워크의 가중치 초기화에 자주 사용됩니다. 이 방법은 초기 가중치가 너무 크거나 작지 않게 하여 학습 과정을 안정화시키는 데 도움을 줍니다.
이러한 함수들은 신경망의 성능과 안정성을 향상시키기 위해 설계되었으며, 모델 구축 시 중요한 역할을 합니다.
networks/basic_module.py
FullyConnectedLayer: 이것은 완전 연결 레이어(또는 밀집 레이어)를 나타냅니다. 신경망에서 입력을 받아 각 입력에 가중치를 곱한 후 합산하여 출력합니다. 이 레이어는 일반적으로 신경망의 출력층이나 중간층에 사용됩니다.
Conv2dLayer: 이것은 2차원 컨볼루션 레이어를 나타냅니다. 이미지와 같은 2차원 데이터에 대해 컨볼루션 연산을 수행하여 특징을 추출합니다. 이 레이어는 주로 이미지 처리에 사용되는 신경망에서 중요한 역할을 합니다.
MappingNet: 이것은 입력 벡터를 다른 차원의 벡터로 매핑하는 네트워크를 나타냅니다. 이는 주로 생성적 적대 신경망(GAN)에서 잠재 공간(latent space)의 벡터를 신경망이 처리할 수 있는 형태로 변환하는 데 사용됩니다.
StyleConv: 이것은 스타일 기반의 컨볼루션 레이어를 나타냅니다. 이 레이어는 스타일 전이나 GAN에서 사용되며, 외부 스타일 정보를 기반으로 이미지의 특징을 변환합니다.
get_style_code: 이 함수는 주어진 입력으로부터 스타일 코드를 생성합니다. 이는 스타일 기반 GAN에서 사용되며, 생성된 이미지의 스타일을 조절하는 데 사용됩니다.
ToRGB: 이것은 신경망의 출력을 RGB 이미지로 변환하는 레이어입니다. 주로 GAN의 생성자에서 사용되며, 신경망이 생성한 특징을 실제 이미지로 변환하는 데 사용됩니다.
DisFromRGB: 이것은 RGB 이미지를 입력으로 받아 신경망의 첫 번째 레이어로 사용됩니다. 주로 GAN의 판별자에서 사용되며, 이미지의 색상 정보를 신경망이 처리할 수 있는 형태로 변환합니다.
DisBlock: 이것은 GAN의 판별자에 사용되는 블록을 나타냅니다. 각 블록은 일련의 컨볼루션 레이어와 활성화 함수 등으로 구성되어 있으며, 입력 이미지의 진위를 판별하는 데 도움을 줍니다.
MinibatchStdLayer: 이 레이어는 미니배치 내의 표준 편차를 계산하여 네트워크의 입력에 추가합니다. 이는 주로 GAN의 판별자에서 사용되어 각 미니배치의 다양성을 증가시키고 모델의 학습을 돕습니다.
코드 이해하기
Conv2dLayerPartial
class Conv2dLayerPartial(nn.Module):
def __init__(self,
in_channels, # Number of input channels.
out_channels, # Number of output channels.
kernel_size, # Width and height of the convolution kernel.
bias = True, # Apply additive bias before the activation function?
activation = 'linear', # Activation function: 'relu', 'lrelu', etc.
up = 1, # Integer upsampling factor.
down = 1, # Integer downsampling factor.
resample_filter = [1,3,3,1], # Low-pass filter to apply when resampling activations.
conv_clamp = None, # Clamp the output to +-X, None = disable clamping.
trainable = True, # Update the weights of this layer during training?
):
super().__init__()
# 평범한 CNN 레이어 생성
self.conv = Conv2dLayer(in_channels, out_channels, kernel_size, bias, activation, up, down, resample_filter,
conv_clamp, trainable)
# 마스크 업데이트에 사용되는 가중치
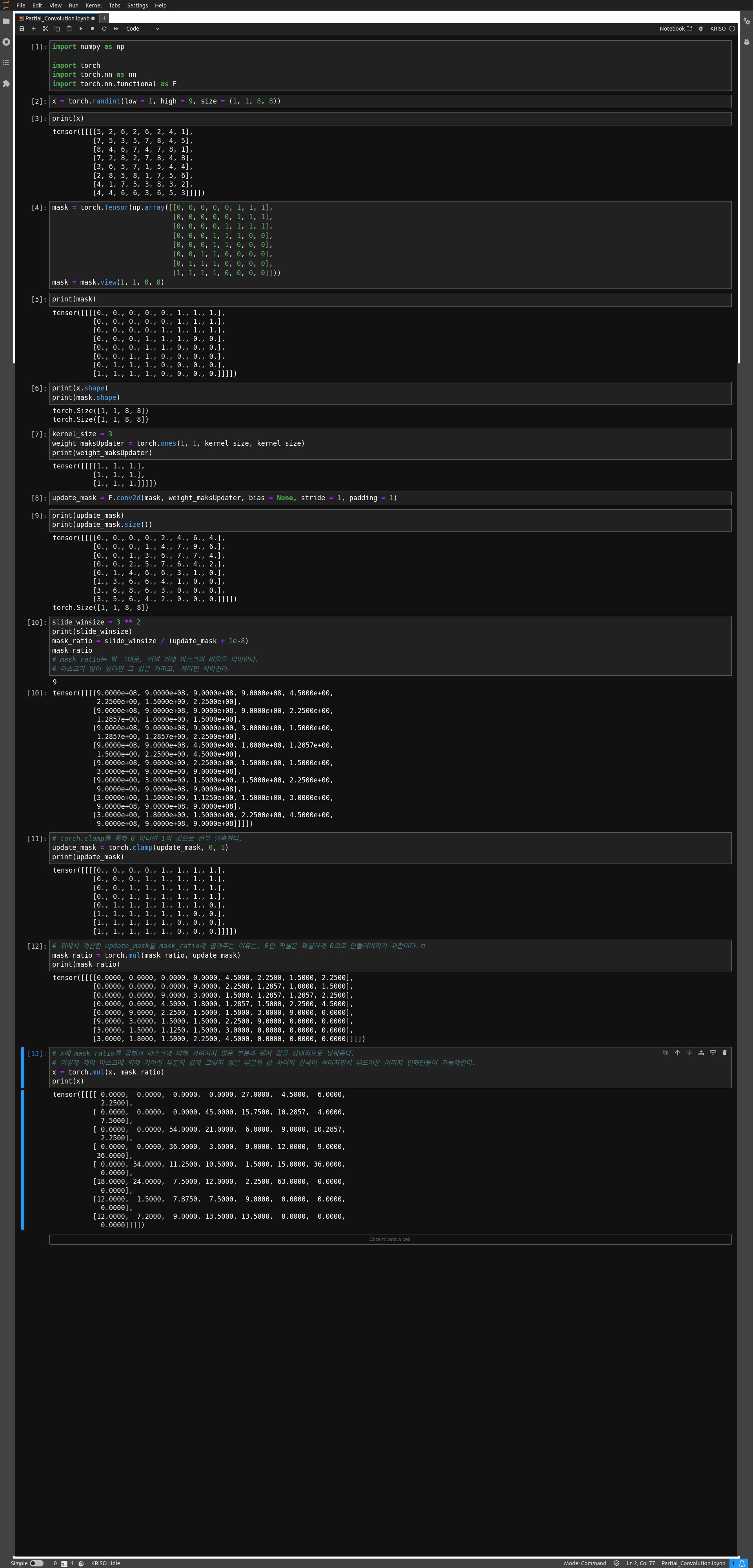
self.weight_maskUpdater = torch.ones(1, 1, kernel_size, kernel_size)
# 슬라이딩 윈도우 사이즈
self.slide_winsize = kernel_size ** 2
# 스트라이드 값(디폴트=1)
self.stride = down
# 패딩 크기
# 커널 사이즈가 홀수일 경우, 이를 2로 나눈 몫
# 커널 사이즈가 짝수일 경우, 0
self.padding = kernel_size // 2 if kernel_size % 2 == 1 else 0
def forward(self, x, mask=None): #x는 입력 텐서, mask는 선택적으로 부여되는 마스크 텐서
if mask is not None: # 마스크 정보가 존재한다면
with torch.no_grad(): # 마스크 처리는 그래디언트 계산을 필요로 하지 않으므로 이를 비활성화 한다
if self.weight_maskUpdater.type() != x.type(): # weight_maskUpdater의 데이터 타입이 x와 다르면, 같은 타입으로 변환한다.
self.weight_maskUpdater = self.weight_maskUpdater.to(x)
# (마스크 텐서, 컨볼루션 웨이트, 바이어스, 스트라이드(1), 패딩)
update_mask = F.conv2d(mask, self.weight_maskUpdater, bias=None, stride=self.stride, padding=self.padding)
mask_ratio = self.slide_winsize / (update_mask + 1e-8) # 커널 / 유효 픽셀 개수
update_mask = torch.clamp(update_mask, 0, 1) # 0 or n -> 0 or 1
mask_ratio = torch.mul(mask_ratio, update_mask) # 0인 부분은 완전히 지워버리는 역할
x = self.conv(x)
x = torch.mul(x, mask_ratio) # 유효 픽셀이 많은 부분의 출력값을 되려 감소시켜 마스크 처리된 곳과 그렇지 않은 곳 사이의 간극을 좁힌다.
return x, update_mask
else: # 마스크 정보가 없다면
x = self.conv(x) # 그냥 기본 컨볼루션을 통과시킨다
return x, None해당 코드에서 설명이 필요한 부분을 정리해보았다.
데이터 타입 확인 및 변환
if self.weight_maskUpdater.type() != x.type():
self.weight_maskUpdater = self.weight_maskUpdater.to(x)목적: 이 코드는 weight_maskUpdater의 데이터 타입이 입력 x의 데이터 타입과 일치하는지 확인하고, 일치하지 않으면 x의 데이터 타입으로 변환합니다.
데이터 타입 불일치 상황: weight_maskUpdater는 초기화 시에 특정 데이터 타입으로 설정됩니다. 만약 이후에 다른 데이터 타입을 가진 입력 x가 주어지면, 두 텐서 간의 연산을 위해 데이터 타입을 일치시켜야 합니다. 예를 들어, weight_maskUpdater가 CPU 텐서로 초기화되었고 x가 GPU 텐서라면, 데이터 타입과 디바이스가 다릅니다. 이 경우 weight_maskUpdater를 x와 같은 디바이스와 데이터 타입으로 변환해야 합니다.
mask_ratio의 의미
mask_ratio = self.slide_winsize / (update_mask + 1e-8)목적: mask_ratio는 마스크 업데이트 후 각 위치에서 유효한 픽셀의 비율을 계산합니다.
계산 방식: slide_winsize는 컨볼루션 윈도우의 총 크기입니다. update_mask는 마스크를 컨볼루션한 후의 값으로, 각 위치에서 유효한 픽셀의 수를 나타냅니다. 1e-8은 0으로 나누는 것을 방지하기 위한 작은 상수입니다. 결과적으로 mask_ratio는 각 위치에서 유효한 픽셀의 비율을 나타내며, 이는 출력에 적용될 가중치로 사용됩니다.
mask_ratio와 update_mask의 곱
mask_ratio = torch.mul(mask_ratio, update_mask)목적: 이 연산은 mask_ratio를 업데이트된 마스크 값에 적용하여, 마스크가 적용된 영역만을 고려하도록 합니다.
이유: update_mask는 0과 1 사이의 값으로, 마스크가 적용된 영역을 나타냅니다. mask_ratio에 update_mask를 곱함으로써, 마스크가 적용되지 않은 영역(즉, update_mask가 0인 영역)은 mask_ratio도 0이 되어 출력에 영향을 주지 않도록 합니다.
출력 x에 mask_ratio를 곱하는 이유
x = torch.mul(x, mask_ratio)mask_ratio의 역할
mask_ratio는 커널 내부의 유효한 픽셀 수에 반비례합니다. 즉, 유효한 픽셀이 많을수록 mask_ratio는 작아집니다.
이는 커널 내에서 유효한 픽셀이 많은 부분이 더 적은 가중치를 받게 함으로써, 마스크가 적용된 부분(유효한 픽셀이 적은 부분)과의 차이를 줄이는 데 도움을 줍니다.
x에 mask_ratio 적용
x에 mask_ratio를 곱할 때, 유효한 픽셀이 많은 부분(즉, mask_ratio가 작은 부분)은 출력 값이 감소합니다.
반대로, 마스크로 가려진 부분(유효한 픽셀이 적은 부분)에서는 mask_ratio가 상대적으로 크기 때문에, 이 부분의 출력 값은 상대적으로 덜 감소합니다.
결과적 영향
이러한 방식은 마스크로 가려진 부분과 가려지지 않은 부분 간의 차이를 줄이는 데 도움을 줍니다. 즉, 마스크로 가려진 부분이 과도하게 강조되는 것이 아니라, 전체적으로 균일한 처리가 이루어지도록 합니다.
특히 이미지 인페인팅과 같은 작업에서는 마스크 처리를 통해 손상된 부분과 손상되지 않은 부분 간의 연속성을 유지하는 것이 중요합니다. 이 방식은 마스크가 적용된 부분을 고려하여 컨볼루션 연산을 조정함으로써, 더 자연스러운 인페인팅 결과를 얻는 데 도움을 줄 수 있습니다.
주피터 노트북으로 구현한 간단한 토이 테스트
WindowAttention
def __init__(self, dim, window_size, num_heads, down_ratio=1, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
# dim: 입력 텐서의 채널 수
# window_size: 윈도우의 크기 ex) (5, 5)
# num_heads: 멀티헤드 어텐션에 사용할 헤드 수
# down_ratio: 다운 샘플링 비율. 1로 하면 다운 샘플링 하지 않는다는 뜻이다.
# qkv_ratio: 쿼리, 키, 밸류 계산에 바이어스를 추가할지의 여부
# qk_scale: 쿼리, 키의 스케일링 팩터.
# attn_drop: 셀프 어텐션 가중치에 적용할 드롭아웃 비율
# proj_drop: 출력에 적용할 드롭 아웃 비율
super().__init__()
self.dim = dim # 입력 채널 수
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads # 셀프 어텐션 헤드 수
head_dim = dim // num_heads # 각 헤드의 차원
self.scale = qk_scale or head_dim ** -0.5 # 스케일링 팩터
# 입력 텐서를 쿼리, 키, 밸류로 변환하는 FCN
self.q = FullyConnectedLayer(in_features=dim, out_features=dim)
self.k = FullyConnectedLayer(in_features=dim, out_features=dim)
self.v = FullyConnectedLayer(in_features=dim, out_features=dim)
# 셀프 어텐션을 거친 후 출력을 추가적으로 변환하는데 사용하는 FNC
self.proj = FullyConnectedLayer(in_features=dim, out_features=dim)
# 셀프 어텐션에 적용할 소프트맥스 (가중치를 확률분포로 변환)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask_windows=None, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
norm_x = F.normalize(x, p=2.0, dim=-1)
q = self.q(norm_x).reshape(B_, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
k = self.k(norm_x).view(B_, -1, self.num_heads, C // self.num_heads).permute(0, 2, 3, 1)
v = self.v(x).view(B_, -1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
attn = (q @ k) * self.scale
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
if mask_windows is not None:
attn_mask_windows = mask_windows.squeeze(-1).unsqueeze(1).unsqueeze(1)
attn = attn + attn_mask_windows.masked_fill(attn_mask_windows == 0, float(-100.0)).masked_fill(
attn_mask_windows == 1, float(0.0))
with torch.no_grad():
mask_windows = torch.clamp(torch.sum(mask_windows, dim=1, keepdim=True), 0, 1).repeat(1, N, 1)
attn = self.softmax(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
return x, mask_windows이론적 설명이 필요한 코드 부분
num_heads의 역할
역할: num_heads는 멀티-헤드 자기 주의에서 사용되는 병렬 주의 헤드의 수를 지정합니다. 멀티-헤드 자기 주의는 입력을 여러 헤드로 분할하여 각 헤드가 다른 부분 공간(subspace)에서 정보를 처리하도록 합니다.
중요성: 각 헤드는 입력 데이터의 다른 특성을 학습할 수 있으므로, 멀티-헤드 구조는 모델이 다양한 관점에서 정보를 통합할 수 있게 해줍니다. 이는 모델의 표현력을 향상시키고, 다양한 유형의 정보를 포착하는 데 도움이 됩니다.
쓰임: 보통 작은 모델에서는 num_heads를 4, 8, 12와 같이 비교적 작은 값으로 설정합니다. 이는 계산 비용을 줄이면서도 다양한 정보를 처리할 수 있도록 합니다. 대규모 모델에서는 num_heads를 16, 32, 64 또는 그 이상으로 설정할 수 있습니다. 더 많은 주의 헤드는 모델이 더 다양한 정보를 동시에 처리할 수 있게 하지만, 계산 비용과 메모리 요구량도 증가시킵니다. 최적의 num_heads 값은 종종 실험을 통해 결정됩니다. 다양한 num_heads 값을 사용하여 모델을 훈련시키고, 검증 세트에서의 성능을 비교하여 최적의 값을 찾습니다. num_heads는 입력 차원 dim과 호환되어야 합니다. 즉, dim은 num_heads로 나누어 떨어져야 합니다. 이는 각 주의 헤드가 처리할 차원의 크기를 동일하게 유지하기 위함입니다.
qkv_bias의 역할과 필요성
역할: qkv_bias는 쿼리(Query), 키(Key), 값(Value) 계산에 바이어스(bias) 항을 추가할지 여부를 결정합니다.
필요성: 바이어스 항은 모델이 더 복잡한 함수를 학습할 수 있도록 도와줍니다. 특히, 입력 데이터가 0에 가까울 때 바이어스는 중요한 역할을 하며, 모델의 학습과 성능 향상에 기여할 수 있습니다.
qk_scale의 역할과 기본값 설정
역할: qk_scale은 쿼리와 키의 내적 결과에 적용되는 스케일링 팩터입니다. 이는 내적 값의 크기를 조절하여 그래디언트의 안정성을 높이는 데 도움을 줍니다.
기본값 설정: 기본적으로 head_dim ** -0.5로 설정됩니다. 이는 내적 값이 크게 증가하는 것을 방지하고, 따라서 소프트맥스 함수의 그래디언트 소실 문제를 줄이는 데 도움이 됩니다.
attn_drop과 proj_drop의 동작
attn_drop: 자기 주의 가중치에 적용되는 드롭아웃입니다. 이는 특정 가중치가 너무 지배적이 되는 것을 방지하고, 모델이 더 견고하게 학습되도록 도와줍니다.
proj_drop: 최종 출력에 적용되는 드롭아웃입니다. 이는 출력 레이어에서의 과적합을 방지하고, 모델의 일반화 능력을 향상시키는 데 도움이 됩니다.
head_dim의 초기화 방식
head_dim은 클래스 내에서만 사용되는 임시 변수이며, 클래스의 다른 부분에서 참조되지 않기 때문에, 클래스 변수(self.head_dim)로 저장할 필요가 없습니다. head_dim은 num_heads로 입력 차원 dim을 나눈 값으로, 각 주의 헤드가 처리할 차원의 크기를 나타냅니다. 클래스 내에서 한 번 계산되고, 필요한 곳에서 직접 사용됩니다.